
Optimizing Age of Information on Real-Life TCP/IP Connections through Reinforcement Learning
In modern communication systems, especially within status update-driven applications such as industrial automation, environmental sensing, and real-time monitoring, the freshness of information is a critical performance metric. The Age of Information (AoI), defined as the time elapsed since the last received data packet was generated, has emerged as a more suitable Key Performance Indicator (KPI) than traditional metrics like delay or throughput. While much of the AoI research to date has focused on theoretical models with known delay distributions, practical implementation over real-life networks remains limited.
This paper introduces a reinforcement learning (RL)-based framework for minimizing AoI in real-world TCP/IP network environments, specifically targeting unpredictable and complex Internet-based links. Using Deep Q-Networks (DQN) and a modified cost function designed to minimize AoI, the system learns optimal update scheduling without requiring prior knowledge of the underlying network topology or delay characteristics.
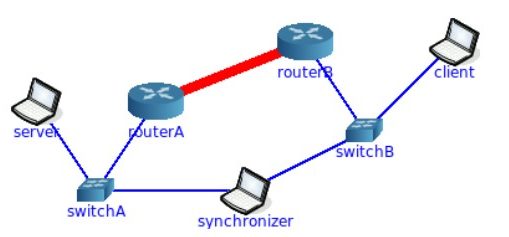
The proposed framework is evaluated using the CORE (Common Open Research Emulator), which enables the emulation of realistic TCP/IP networks with adjustable delay and bandwidth constraints. A client-server architecture is implemented, where the client periodically generates timestamped status updates and the server, based on observed AoI, learns to issue “pause” or “resume” commands to the client. The learning process is driven by a custom reinforcement learning setup with continuous state-space and discrete action-space, where AoI is treated as a cost to be minimized.
Through extensive experimentation, the study demonstrates that:
-
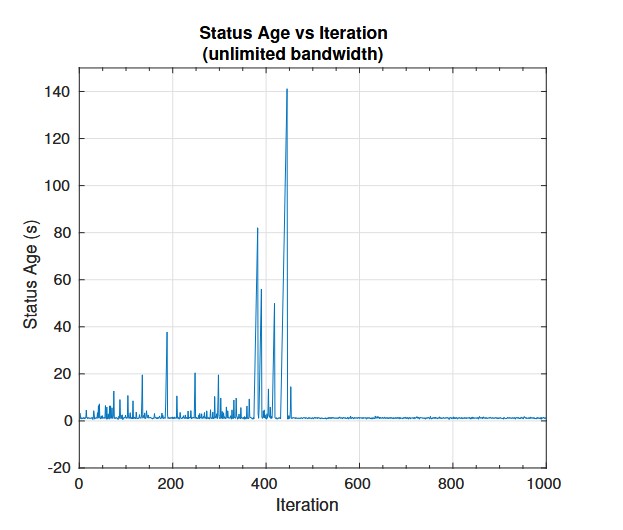
In uncongested, high-bandwidth networks, continuous data transmission (resume action) is ideal, as no queuing delay accumulates.
-
In bandwidth-limited networks, AoI exhibits a non-monotonic behavior with respect to sampling rate—highlighting that overly frequent updates can degrade freshness due to queuing.
-
The DQN agent successfully learns the optimal update policy over time, converging to ideal AoI-minimizing strategies even in stochastic environments with unknown delay distributions.
To ensure stability and scalability of learning, the study integrates established RL enhancements such as Double DQN, experience replay, and ε-greedy exploration. The model converges to the theoretical optimal Q-value for resuming updates in uncongested settings, verifying the correctness of the approach. It further confirms that learning-based network control can dynamically adapt to changing network conditions to keep information fresh.
This work is the first to demonstrate the practical application of deep reinforcement learning to AoI optimization in real-life TCP/IP communication, bridging the gap between theory and deployment. It lays the foundation for general-purpose, model-free AoI optimization engines capable of self-adaptation across diverse network infrastructures. The approach is scalable and compatible with both cloud-based and edge IoT deployments, making it highly relevant for next-generation Internet-of-Things (IoT), cyber-physical systems, and time-critical data services.
For more information, please click here!
![]()